A few months back, the Allen Institute of Artificial Intelligence organized an AI Question Answering Kaggle challenge. The challenge involved answering 8th Grade multiple choice questions on Physics, Chemistry and Biology. I was part of the lab team competing in the challenge. The questions were pretty hard; for answering the questions, the system would need background knowledge in Sciences, ability to infer statements from known facts, and apply general facts to specific examples, e.g., it would need to understand that nails conduct electricity since iron conducts electricity and nails are made of iron. The winning entry could answer only about 60% of the questions correctly, and that too, I suspect, using information retrieval. Deep Learning, in my opinion, is not yet developed enough to tackle this hard problem, but it has takes a few steps in this direction with Memory Networks.
Memory Networks
The task involves answering questions from the simple synthetic bAbI dataset. Each question comes with a set of facts, a subset of which are useful for answering the question. For example, ‘Mary moved to the bathroom’ ‘John went to the hallway’ are Facts. ‘Where is Mary ?’ is the question and the answer is ‘bathroom’. Out of the two facts, ‘Mary moved to the bathroom’ is the supportive fact since it is required for answering the question. The neural network needs to understand the question, and use the supporting facts to answer the question. Memory Network is the name of the machine learning architecture first proposed by Weston et. al for addressing this task.
The memory network consists of a memory array and additionally has four parts, the input feature map, the generalization component which updates old memories, the output feature map, and the response which converts the output feature map to text.
Implementation Details
Weston et. al use a simple neural network embedding model for implementing the memory network. The input layer simply consists of plain text facts stored in an array. They do not use the generalization module, and most action happens in the output and response component. The output module computes features by searching for 

For k = 1,
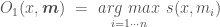
where 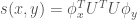


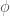
For 
![[x,m_{o1}]](https://s0.wp.com/latex.php?latex=%5Bx%2Cm_%7Bo1%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![O_2([x,m_{o1}],\boldsymbol{m}) \ = \ \underset{i = 1\cdots n}{arg \ max} \ s([x,m_{o1}],m_i)](https://s0.wp.com/latex.php?latex=O_2%28%5Bx%2Cm_%7Bo1%7D%5D%2C%5Cboldsymbol%7Bm%7D%29+%5C+%3D+%5C+%C2%A0%5Cunderset%7Bi+%3D+1%5Ccdots+n%7D%7Barg+%5C+max%7D+%5C+s%28%5Bx%2Cm_%7Bo1%7D%5D%2Cm_i%29&bg=ffffff&fg=444444&s=0&c=20201002)
The response module outputs a single word which maximizes the score (dot product) between the vocabulary words and the list.
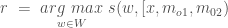
An RNN can be used, if instead of a single word output, a phrase or sentence is expected.
Training
Margin loss is used for learning the embedding matrix $U$, specifically the model is trained so that the score between the correct memory and question is more than the score between the false memory and the question by margin

The loss function is given by
![\sum_{f_1 \neq m_{o1}} max(0, \gamma - s(x,m_{o1}) + s(x,f_1)) \\ + \sum_{f_2 \neq m_{o2}} max(0, \gamma - s([x,m_{o1}],m_{o2}) + s([x,m_{o1}],f_2)) \\ + \sum_{f_3 \neq m_{o1}} max(0, \gamma - s([x,m_{o1},m_{o2}],r) + s([x,m_{o1},m_{o2}],f_3))](https://s0.wp.com/latex.php?latex=%5Csum_%7Bf_1+%5Cneq+m_%7Bo1%7D%7D+max%280%2C+%5Cgamma+-+s%28x%2Cm_%7Bo1%7D%29+%2B+s%28x%2Cf_1%29%29+%C2%A0%5C%5C+%2B%C2%A0%5Csum_%7Bf_2+%5Cneq+m_%7Bo2%7D%7D+max%280%2C+%5Cgamma+-+s%28%5Bx%2Cm_%7Bo1%7D%5D%2Cm_%7Bo2%7D%29+%2B+s%28%5Bx%2Cm_%7Bo1%7D%5D%2Cf_2%29%29+%C2%A0%5C%5C+%2B%C2%A0%5Csum_%7Bf_3+%5Cneq+m_%7Bo1%7D%7D+max%280%2C+%5Cgamma+-+s%28%5Bx%2Cm_%7Bo1%7D%2Cm_%7Bo2%7D%5D%2Cr%29+%2B+s%28%5Bx%2Cm_%7Bo1%7D%2Cm_%7Bo2%7D%5D%2Cf_3%29%29&bg=ffffff&fg=444444&s=0&c=20201002)
If the number of facts is too large, one may need to first narrow down the set using a reverse index (information retrieval model), or by first clustering and then selecting the appropriate cluster.
As seen in the objective function, the algorithm requires knowledge of the supporting memories which may not be available in a real world setting. Learning without this knowledge is termed as weak learning. End-to-End Memory Networks (Sukhbataar et al) attempts to address this problem by replacing the strong supervision, by weighting the memories and learning those weights using end-to-end training.
A straightforward implementation of the memory network using the Keras library is available here. Note that it uses an LSTM for generating the answer instead of the dot product. In subsequent posts we will explore the use of attention models for improving memory networks.
